The Inner Mechanism of Byte Pair Encoding
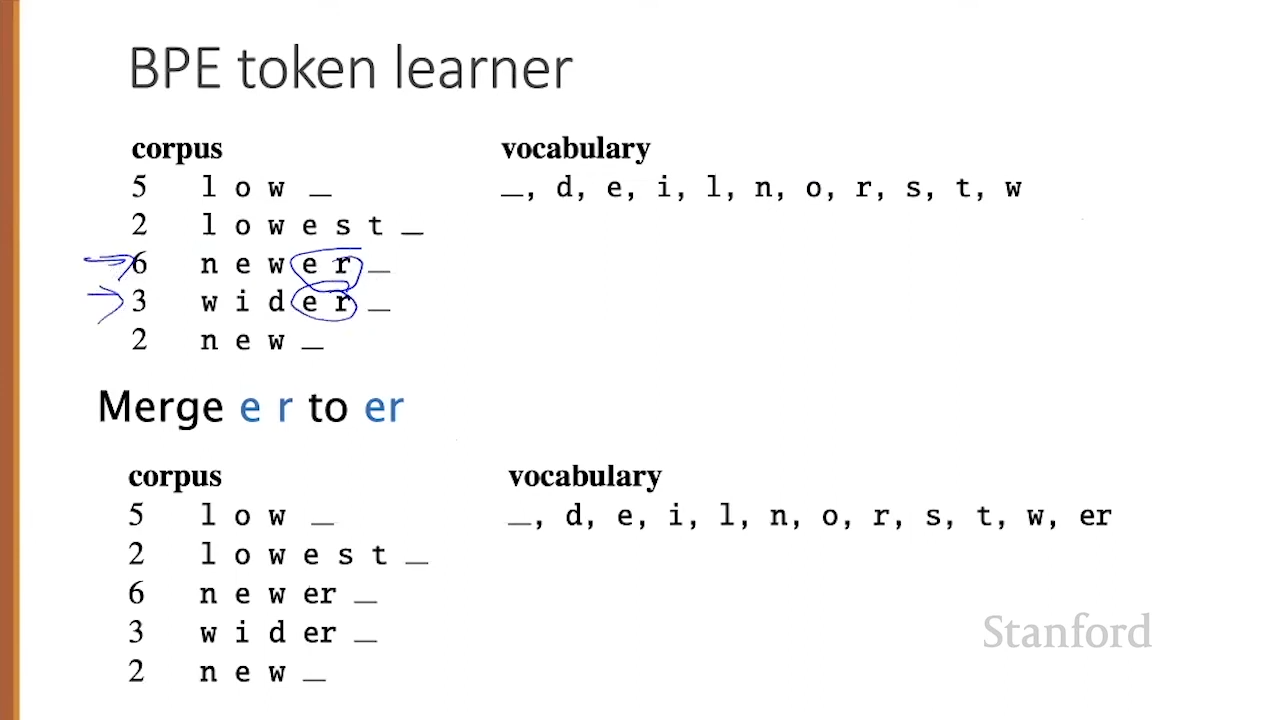
BPE is a subword tokenization technique that's used to split words into smaller, more frequent subunits, which reduces vocabulary size while still being able to represent a large variety of words. BPE was used in models such as GPT-1 and GPT-2 for tokenization
January 2025